Overview of the code
At this point, you should have been able to successfully run the Derecho demo code. If not, please head back to the earlier sections before continuing on with this component.
So what does the code do?
The demo code that you’ve just successfully downloaded
and run is meant to simulate a real-world
Internet-of-Things + Machine Learning pipeline. It contains a set of
clients, which simulate drones or robots taking photos in the wild and
identifying the plants and animals in the photos. These clients don’t
have much local knowledge or computation power, so they submit each
photo to a cloud service to do the job. The rest of the demo is the
cloud service, implemented as a Derecho microservice. Internally, it
contains two components (“subgroups” in Derecho-speak): a “function
tier” and a “categorizer tier”. Each node in the function tier runs
Google’s gRPC service to handle incoming inference
requests (i.e. requests to identify what is contained in the photo
using a CNN model) from the client. Upon receiving such a request, the
function tier node forwards it to a categorizer node with knowledge
relevant to that image, using Derecho’s p2p_query. Image knowledge
is represented by many CNN models, each of which handles a specific
type of object - there is a flower model, a pets model, and so on. In
the categorizer tier subgroup, each shard is responsible for a
partition of the models; the nodes within a shard all serve the same
set of models. Thus, when a function tier node receives an inference
request, it must forward it to the shard (or shards) with the right
model for identifying the image, but it can choose any node within
that shard to contact. We use the MxNet
framework for our machine learning component.
This pipeline is illustrated in this image:
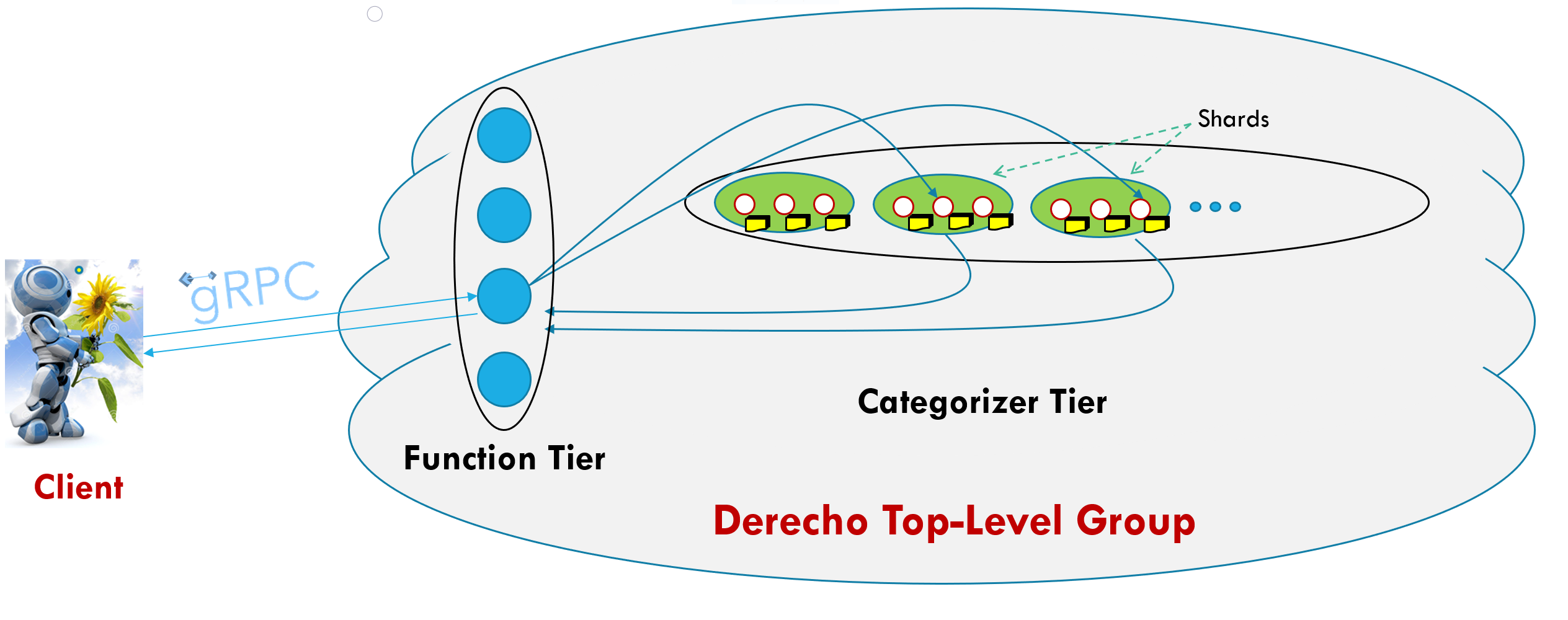
Here we see the client is represented by a picture of a robot, which communicates via Google’s gRPC with the Derecho application. The vertical circles within the Derecho cloud are the function tier, which communicate with the sharded categorizer tier. Each collection of three small circles in the categorizer tier represents a single shard of the categorizer tier, responsible for a set of possible recognition tasks. The function tier has to intelligently select the appropriate categorizer tier shard to handle the client’s request.
Looking at the code
Let’s navigate to the demo code you’ve downloaded and inspect the directory structure contained therein:
$ tree
.
├── CMakeLists.txt
├── include
│ ├── derecho-component
│ │ ├── blob.hpp
│ │ ├── categorizer_tier.hpp
│ │ ├── function_tier.hpp
│ │ └── server_logic.hpp
│ ├── grpc-component
│ │ ├── client_logic.hpp
│ │ └── function_tier-grpc.hpp
│ └── mxnet-component
│ ├── inference_engine.hpp
│ └── utils.hpp
├── README.md
├── src
│ ├── CMakeLists.txt
│ ├── derecho-component
│ │ ├── blob.cpp
│ │ ├── categorizer_tier.cpp
│ │ ├── function_tier.cpp
│ │ └── server_logic.cpp
│ ├── grpc-component
│ │ ├── client_logic.cpp
│ │ └── function_tier-grpc.cpp
│ ├── main.cpp
│ ├── mxnet-component
│ │ └── inference_engine.cpp
│ └── protos
│ └── function_tier.proto
...We’ve left off the output describing the test directories, which we’ll
get to later! As the directory structure demonstrates, this demo (as
with all of Derecho) is configured as a cmake
project. We’ve broken the headers into an include directory1,
and the sources into a src directory. Each are further broken down
into three directories based on the role they serve; gRPC
functionality is in grpc-component, MxNet functionality is in the
mxnet-component, and the Derecho service itself lives in the
derecho-component. Doing a quick sloccount of the src directory:
$ sloccount src/
SLOC Directory SLOC-by-Language (Sorted)
414 grpc-component cpp=414
376 derecho-component cpp=376
113 mxnet-component cpp=113
45 top_dir cpp=45
0 protos (none)
Totals grouped by language (dominant language first):
cpp: 948 (100.00%)Indicates that, by weight, much of our demo’s complexity actually come
from the gRPC component! This is due to the design of gRPC; we
have to manually handle chunking data, reassembling it, and ensuring
the types line up correctly. Derecho, by contrast, handles all of
this automatically. In the next section, we’ll turn our attention to the Derecho code itself, starting with the server logic.
- We’ll have
cmakeinject theincludedirectory into the include path of our project, so all our#includedirectives will use the<system_path>search syntax. [return]